
Mastering the game of Go without human knowledge
The paper propose AlphaGo Zero which is known as self-playing without human knowledge.
Reinforcement learning in AlphaGo Zero
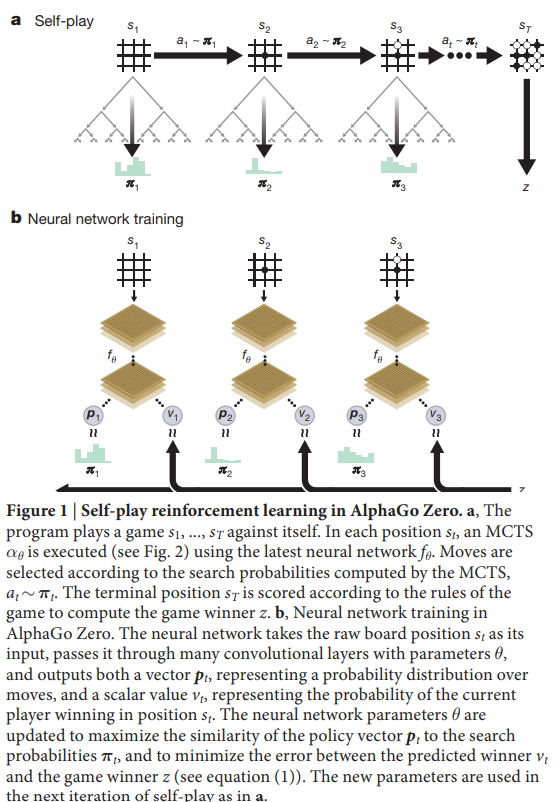
$$ (p, v) = f_{\theta} $$
$$ l = (z - v)^2 - \pi^T log(p) + c||\theta||^2 $$
Mastering Chess and Shogi by Self-Play with a General Reinforcement Learning Algorithm
The paper propose AlphaZero which is known as self-playing to compete any kinds of board game.