
Neural Tangent Kernel(NTK)
![]()
“In short, NTK represent the changes of the weights before and after the gradient descent update”
Let’s start the journey of revealing the black-box neural networks.
Setup a Neural Network
First of all, we need to define a simple neural network with 2 hidden layers
$$ y(x, w)$$
where $y$ is the neural network with weights $w \in \mathbb{R}^m$ and, ${ x, \bar{y} }_N$ is the dataset which is a set of the input data and the output data with $N$ data points. Since we focus on analyze the weight $w$, we simplify the notation $y(x, w)$ as $y(w)$
Suppose we have a regression task on the network $y(w)$, define
$$L(w) = \frac{1}{N} \frac{1}{2} \Vert y(w) - \bar{y} \Vert^2_2 $$
where $L(w)$ is our object loss which we want to minimize. Since the term $\frac{1}{N}$ is regardless to our goal, just ignore it and we get a simpler loss function
$$L(w) = \frac{1}{2} \Vert y(w) - \bar{y} \Vert^2_2 $$
To The Limit of Infinite Width
In order to measure the difference of the weights during training the neural network, we define a normalized metric as following
$$\frac{\Vert w_n - w_0 \Vert_2}{\Vert w_0 \Vert_2}$$
where $w_n$ and $w_0$ are the weights at n-th training iteration and the initial weights. $\Vert w_n - w_0 \Vert_2$ means the quantity of the differnce between parameters $w_n$ and $w_0$ and it is normalized by the 2-norm $\Vert w_0 \Vert_2$
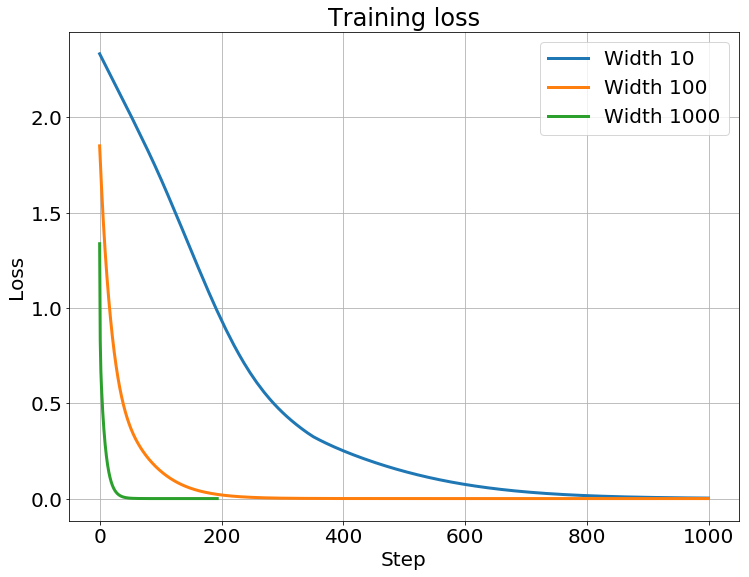
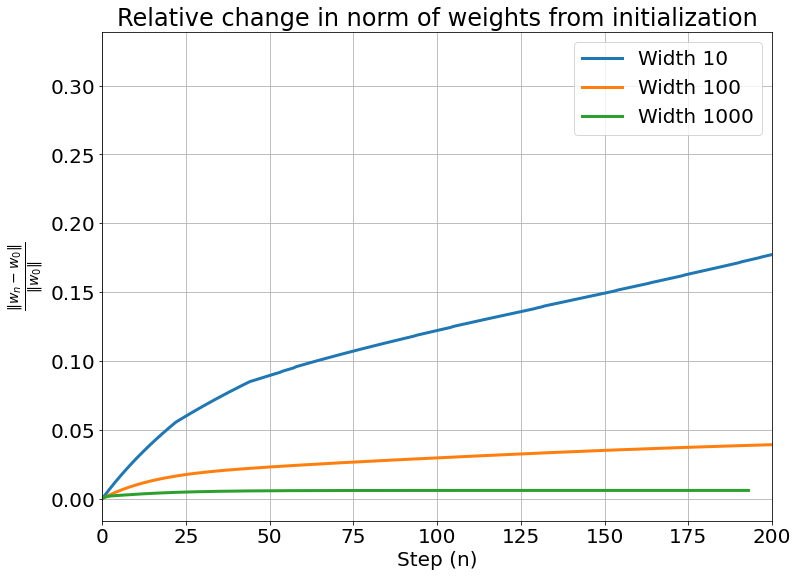
As we can see, the difference of the weights during training decrease as the width of network grows. As a result, the trained weights should be very close to the inital weights $w_0$ as the width of network goes to infinity.
Apply Taylor Expansion
We’ve known the Taylor expansion is
$$f(x) = \sum_{n=0}^{\infty} \ \frac{f^{n}(a)}{n!} (x - a)^{n}$$
A function $f(w)$ expanded on the $w_0$ with first order approximation is
$$f(w) \approx f(w_0) + \frac{df(w_0)}{dw} (w - w_0)$$
It is trivial that if $w$ is a vector, we need to replace the derivative $\frac{df(w_0)}{dw}$ with gradient $\nabla_{w} f(w_0)^{\top}$
$$f(w) \approx f(w_0) + \nabla_{w} f(w_0)^{\top} \ (w - w_0)$$
Apply to the network $y(w)$
$$y(w) \approx y(w_0) + \nabla_{w} y(w_0)^{\top} \ (w - w_0)$$
where $\nabla_{w} y(w_0)$ and $y(w_0)$ are constants.
Thus, the Taylor expansion of $y(w)$ is just a linear model. Though the expansion around $w_0$ is regardless to the proof of NTK, it is still a useful tool to analyze the accuracy of the linear approximation with infinite-wide network.
However, the most difficult thing is how can we guarantee the approximation is accurate enough? It is so complex that I wouldn’t put it in this article but I will provide an intuitive explaination of what does NTK mean? in the following article. Please keep reading it if you are interested in it.
An Simpler Explaination Without Flow
Simply, we only consider a 1-dimension network $f(x, w), \ w, x, \bar{y} \in \mathbb{R}$ for a dataset $x \in X, \ \bar{y} \in \bar{Y}$ which are input data points and output data points respectively.
First of all, let’s define the loss function of a neural network
$$L_{1}(x, w) = \frac{1}{2} \Vert f(x, w) - \bar{y} \Vert^2_2$$
The gradient descent is
$$ w_{t+1} = w_0 + \eta \ \frac{dL_1(x, w)}{dw} $$ $$ = w_0 + \eta (f(x, w) - \bar{y}) \frac{df(x, w)}{dw} $$
where $\eta$ is the learning rate.
NTK represent the changes of the weights before and after the gradient descent update. Thus, the changes of weights can be defined as
$$lim_{\eta \to 0} \frac{f(x, w + \eta \ \frac{dL_1(x’, w)}{dw}) - f(x, w)}{\eta}$$
$$= lim_{\eta \to 0} \frac{f(x, w + \eta \ (f(x’, w) - \bar{y}) \frac{df(x’, w)}{dw}) - f(x, w)}{\eta}$$
To simplify the notation, let $\eta \ (f(x’, w) - \bar{y}) \frac{df(x’, w)}{dw}) = \Delta w$.
We can derive
$$ lim_{\eta \to 0} \frac{f(x, w + \eta \ (f(x’, w) - \bar{y}) \frac{df(x’, w)}{dw}) - f(x, w)}{\eta} $$
$$ = lim_{\eta \to 0} \frac{f(x, w + \Delta w) - f(x, w)}{\eta} $$
Suppose the learning rate $\eta$ is small enough and thus, $w \approx w + \Delta w$. We can expand around $w + \Delta w$ with Taylor expansion
$$f(x, w) \approx f(x, w + \Delta w) + \frac{df(x, w + \Delta w)}{dw} (w - (w + \Delta w))$$
$$ = f(x, w + \Delta w) - \frac{df(x, w + \Delta w)}{dw}\Delta w$$
We can get
$$ lim_{\eta \to 0} \frac{f(x, w + \Delta w) - f(x, w)}{\eta} $$
$$ = lim_{\eta \to 0} \frac{f(x, w + \Delta w) - (f(x, w + \Delta w) - \frac{df(x, w + \Delta w)}{dw} \Delta w)}{\eta} $$
$$ = lim_{\eta \to 0} \ \frac{1}{\eta} \frac{df(x, w + \Delta w)}{dw} \Delta w $$
$$ = lim_{\eta \to 0} \ \frac{df(x, w + \eta \ (f(x’, w) - \bar{y}) \frac{df(x’, w)}{dw})}{dw} \ (f(x’, w) - \bar{y}) \frac{df(x’, w)}{dw} $$
$$ = \frac{df(x, w)}{dw} \ (f(x’, w) - \bar{y}) \frac{df(x’, w)}{dw} $$
Since the weight almost not change, let $w = w_0$ and NTK is defined as
$$k_{1}^{NTK}(x, x’) = \frac{df(x,w)}{dw} \frac{df(x’, w)}{dw} = \frac{df(x,w_0)}{dw} \frac{df(x’, w_0)}{dw}$$
Since $f(x’, w) - \bar{y}$ would be very close to 0 while MSE is close to 0, we can simply ignore it. It is trivial that NTK represent the changes of weights before and after gradient descent. It measure the difference of weights quantitatively and thus we can approximate the process of gradient descent with Gaussian process.
Flow And Vector Field
So far, we’ve shown the neural tangent kernel on 1-width network. To move forward to the infinite-wide network, we need 2 tools to help us analyzing the process of gradient descent in high-dimensionalal. As a result, before diving into NTK more deeply, we need to understand what is Gradient Flow and Vector Field.
Vector Field
Define a space $\chi \in \mathbb{R}^d$ with d dimensions and a point of the space $x \in \mathbb{R}^d$. A hyperplane $f(x) \ f: \chi \to \mathbb{R}$. As we want to find the global minimal point $x^*$
$$x^* = \mathop{\arg\min}_{x \in X} \ f(x)$$
The gradient of the hyperplane $\nabla_x \ f: \chi \to \mathbb{R}^d$ represent the gradients of each point on the hyperplane $f$.
Then, we define a vector field $F: \chi \to \mathbb{R}^d$ assigning the velocity vector to each points of the space. Mathmatically, the vector field $F$ has the same function space as the gradient $\nabla_x f$. As a result, we can also see the gradient $\nabla_x f$ as a vector field $- \nabla_x f = F(x)$ which assigns the velocity vector $v \in \mathbb{R}$ to each point $x \in \chi$.
$$F(x) = - \nabla_x f(x) = v$$
A hyperplane and the gradients can be illustrated as the following figure. The orange surface represents the hyperplane $f$ and the corresponding gradient $\nabla_x f$ of each points $x \in \chi$ on the hyperplane $f$ is the blue arrows in the bottom. Note that the gradients $\nabla_x f(x)$ here are ascent while gradients of our optimization problem are descent $- \nabla_x f(x)$. They have oppsite direction. Intuitively, the gradients represent the direction and steepness of the points on the hyperplane while the vector field is the velocity vector of the points. Mathmatically, the gradients and the vector field have the same function space, so we let them be equal but not due to the physical perspective.

Then we introduce another variable time. Let $c(t)$ for $c: \mathbb{R} \to \mathbb{R}^d$ represent the dynamics of along the time $t$. The function $c(t)$ gives the position in the space $\chi \in \mathbb{R}^d$ along time $t$.
As a result, we know
$$c(t + \delta) = c(t) + \delta F(c(t)) = c(t) - \delta \nabla_x f(c(t))$$
where $\delta$ represent the time-step of 2 positions. $\delta F(c(t)) = - \delta \nabla_x f(c(t))$ means time products velocity vector and then get the movment vector during the time $\delta$.
Gradient Flow
The gradient flow is defined as
$$\dot{X}(t) = F(c(t)) = - \nabla_x f(c(t)) = - \nabla_x f(c(t))\dot{c}(t) = - \nabla_x f(c(t)) \frac{dc(t)}{dt}$$
The gradient flow describe changing gradients along time.
Combined With Gradient Flow
We’ve know the update of the gradient descent is
$$w_{t+1} = w_t - \eta \nabla_{w} L(w_t)$$
Let the function $w(t) = w_t$ and define the gradient flow over weights is $\dot{w}(t)$
$$\dot{w}(t) = - \nabla_{w} L(w(t))$$
Actually, the meaning of the gradient flow $\dot{w}(t) = \frac{dw(t)}{dt}$ is likey the changing direction of gradient descent along time.
We expand the gradient of the loss function with chain rule
$$ \dot{w}(t) = - \nabla_{w} L(w(t)) $$
$$ = - \nabla_{w} \frac{1}{2} \Vert y(w(t)) - \bar{y} \Vert^2_2 $$
$$ = - \frac{1}{2} \cdot 2 \nabla_{w} y(w(t)) (y(w(t)) - \bar{y}) $$
$$ = - \nabla_{w} y(w(t)) (y(w(t)) - \bar{y}) $$
Now we can derive the flow of the network $\dot{y}(w(t))$
$$ \dot{y}(w(t)) = \nabla_{w} y(w(t))^{\top} \dot{w}(t) $$
$$ = -\nabla_{w} y(w(t))^{\top} \nabla_{w} y(w) (y(w(t)) - \bar{y}) $$
$$ = - \nabla_{w} y(w(t))^{\top} \nabla_{w} y(w(t))(y(w(t)) - \bar{y}) $$
To simplify the notation, we replace the dynamics $w(t)$ with $w_t$.
$$w(t) = w_t$$
Thus, we get
$$\dot{y}(w_t) = - \nabla_{w} y(w_t)^{\top} \nabla_{w} y(w_t)(y(w_t) - \bar{y})$$
However, we’ve known the mathmatical form of the flow $\dot{y}(w_t)$, but what’s the meaning of the flow $\dot{y}(w_t)$? Well, we can see the updated weights $w_t$ during the gradient descent as a trajectory in a high-dimensional space. Since the learning rate $\eta$ is quite small, the the difference of weights $w_t$ between before and after the gradient descent is very small. As a result, we can see the discrete porgress of the graient descent as a continuous trjectory like the following figure. The flow over the neural network $\dot{y}(w_t)$ is actually the tangent line of $w_t$. The flow $\dot{y}(w_t)$ describe the velocity vector of the point $w_t$ and can predicts close-enough next point $w_{t+1}$.
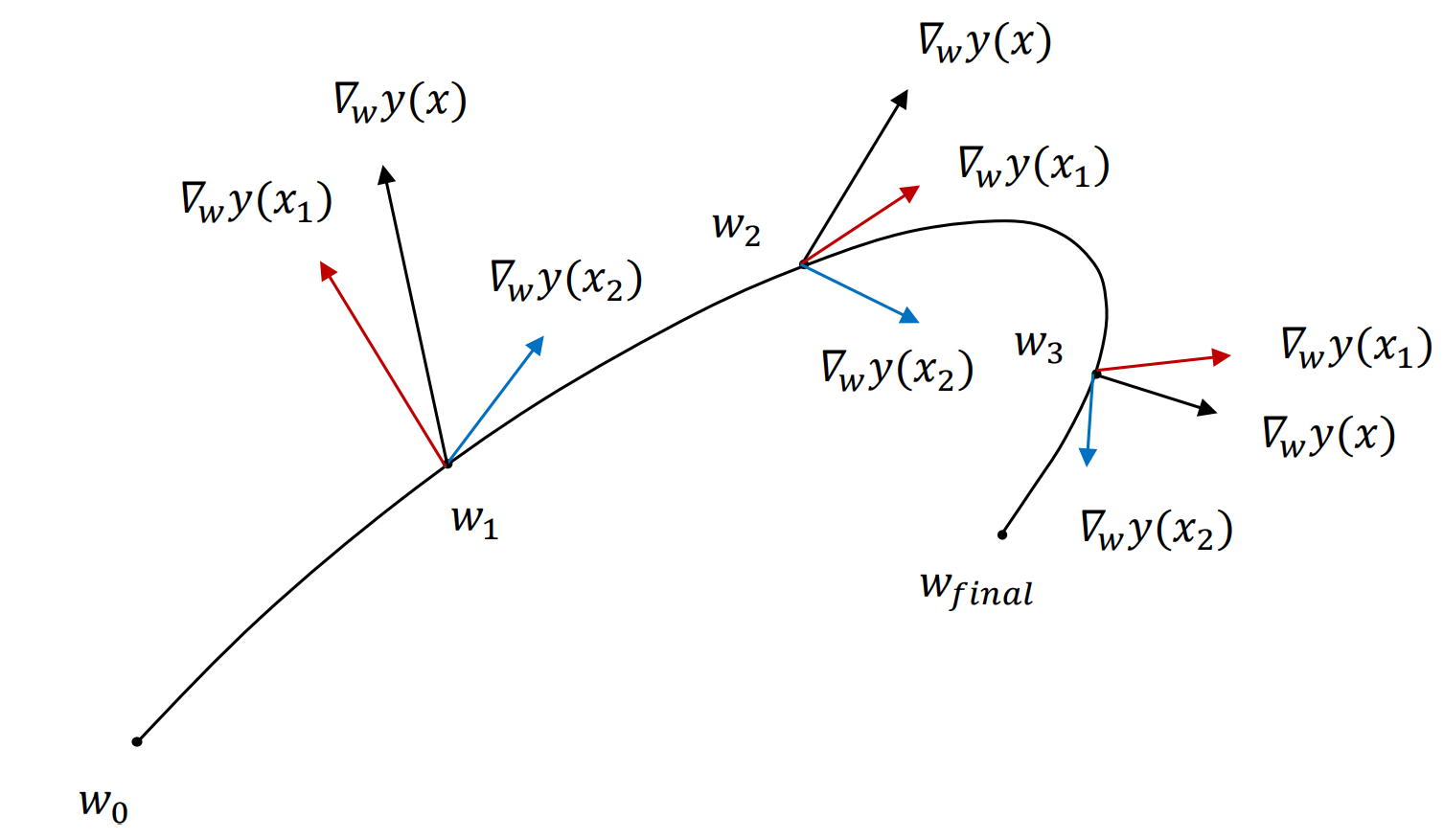
Since $y(w_t) - \bar{y}$ would be very close to 0, too while MSE is close to 0, we can simply ignore it.
Actually, we are now very close to the neural tangent kernel(NTK). The NTK is a kernel matrix defined as
$$\boldsymbol{K_{NTK}(x, x’)} = \nabla_{w} y(x, w_t)^{\top} \nabla_{w} y(x’, w_t)$$
Since the weights of the infinite-wide network doesn’t change during the training.
$$y(w_t) \approx y(w_0)$$
We get
$$ -\nabla_{w} y(w_t)^{\top} \nabla_{w} y(w_t) \approx -\nabla_{w} y(w_0)^{\top} \nabla_{w} y(w_0) = -\nabla_{w} y(x, w_0)^{\top} \nabla_{w} y(x’, w_0) $$
$$= \boldsymbol{K_{NTK}(x, x’)}$$
Again, $\boldsymbol{K_{NTK}(x, x’)}$ is the Neural Tangent Kernel, NTK.
The way here to measure the distance between 2 tangents is the Cosine Similarity with inner product. The cosine value of 2 identical vector is 1 and 2 orthorgonal vectors is 0 which are totally different. With an additional minus sign, we can regard the negative similarity as a kind of distance.
To summary, the weights of an infinite-wide network almost don’t change during training. As a result, the kernel always stay almost the same. We can use NTK to analyze many properties of neural network and the neural networks are no longer black boxes.
Papers
NNGP
NTK
Reference
Thank for the following posts / people sincerely.
Gaussian Distribution
NNGP
- Deep Gaussian Processes
- Gonzalo Mateo García - Deep Neural Networks as Gaussian Processes
- Deep Gaussian Processes for Machine Learning
NTK
- Understanding the Neural Tangent Kernel By Rajat’s Blog
- Code for the blog rajatvd/NTK
- Ultra-Wide Deep Nets and the Neural Tangent Kernel (NTK)
- CMU ML Blog: Ultra-Wide Deep Nets and the Neural Tangent Kernel (NTK)
- Some Intuition on the Neural Tangent Kernel
- 直观理解Neural Tangent Kernel
Flow
Taylor Expansion